I am extremely delighted to have participated in the AWS re:Invent re:Cap event held in Hong Kong, which provided me with exposure to the latest AI solutions offered by AWS.
In this article, I will first discuss the advantages of deploying models in production using SageMaker after training them locally. I would like to express my gratitude to Raymond Tsang for providing valuable insights.
Next, I will delve into the benefits of training models using SageMaker as opposed to local training. I would like to thank Yanwei CUI for sharing their insights.
Lastly, I will explain a more efficient trading strategy architecture, with special thanks to Wing So for their valuable input.
1. The Benefits of Deploying Models in Production with SageMaker
The greatest advantage of SageMaker lies in its data security, auto scaling, and container deployment capabilities. If high data security, handling sudden traffic spikes, and agile development processes are required, leveraging these advantages of SageMaker can significantly accelerate development and deployment timelines.
However, after training models locally, can one deploy them in production using SageMaker? In other words, is it possible to utilize only specific functionalities of SageMaker?
Answer: Yes, it is possible to use only certain functionalities of SageMaker.
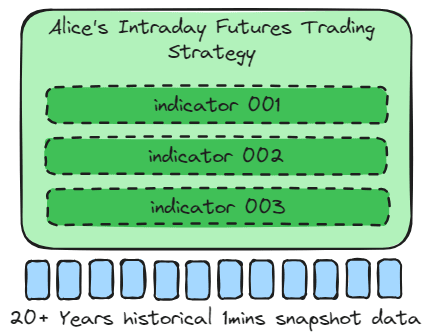
In the case of my use case, “Alice’s Intraday Futures Trading Strategy,” which is a daily trading strategy model with fixed trading times and a predictable number of requests, the model is susceptible to market sentiment and unexpected news events, necessitating monthly model updates.
In such a scenario, deploying the model in a production environment using SageMaker offers the following advantages:
SageMaker allows for container deployment, making it easier to manage custom inference code within the deployment image.
SageMaker’s endpoint supports version iterations, facilitating agile development processes.
SageMaker supports multi-model deployment in a single endpoint, enabling easier management of multiple model interfaces.
While local model training is preferred in my use case, there are still advantages to using SageMaker for model training.
2. The Advantages of Training Models with SageMaker
If there are two RTX3080 graphics cards available on the local server, is there still a need to use AWS SageMaker for training models? In other words, can one replace the pay-as-you-go model training of SageMaker with a one-time higher fixed cost?
Answer: Yes, it is possible. However, if one wishes to avoid the time-consuming process of hardware deployment or simply desires to utilize higher-end hardware for a shorter duration, training models using SageMaker is more suitable.
Furthermore, SageMaker optimizes data-batch processing and floating-point operations to accelerate model training speed.
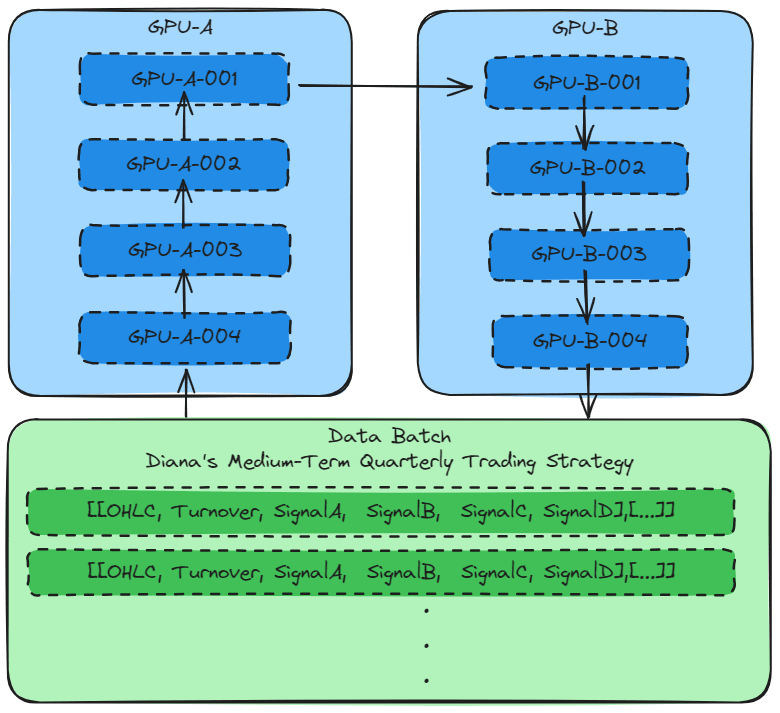
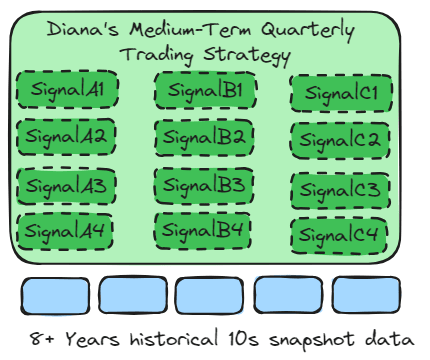
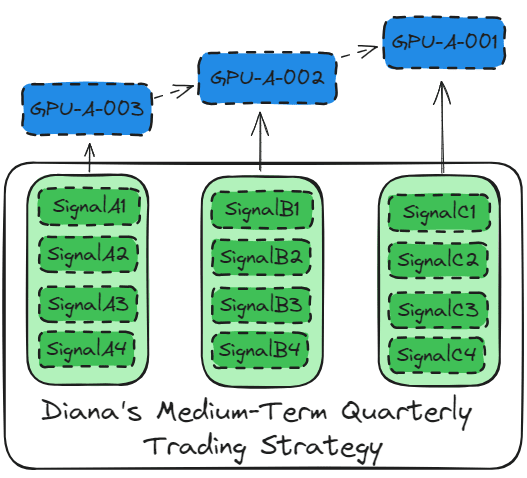
In the case of my use case, “Diana’s Medium-Term Quarterly Trading Strategy,” which involves multi-asset trading in four major markets (US stocks, Hong Kong stocks, US bonds, and USD currency), the optimized data-batch processing of SageMaker can be utilized for the four main markets.
Additionally, the optimized floating-point operations of SageMaker can be applied to the three core technical indicators within the model (high dividend stocks, low volatility, and capital accumulation).
Therefore, gaming graphics cards have limitations when it comes to model training.
3. A More Efficient Trading Strategy Architecture
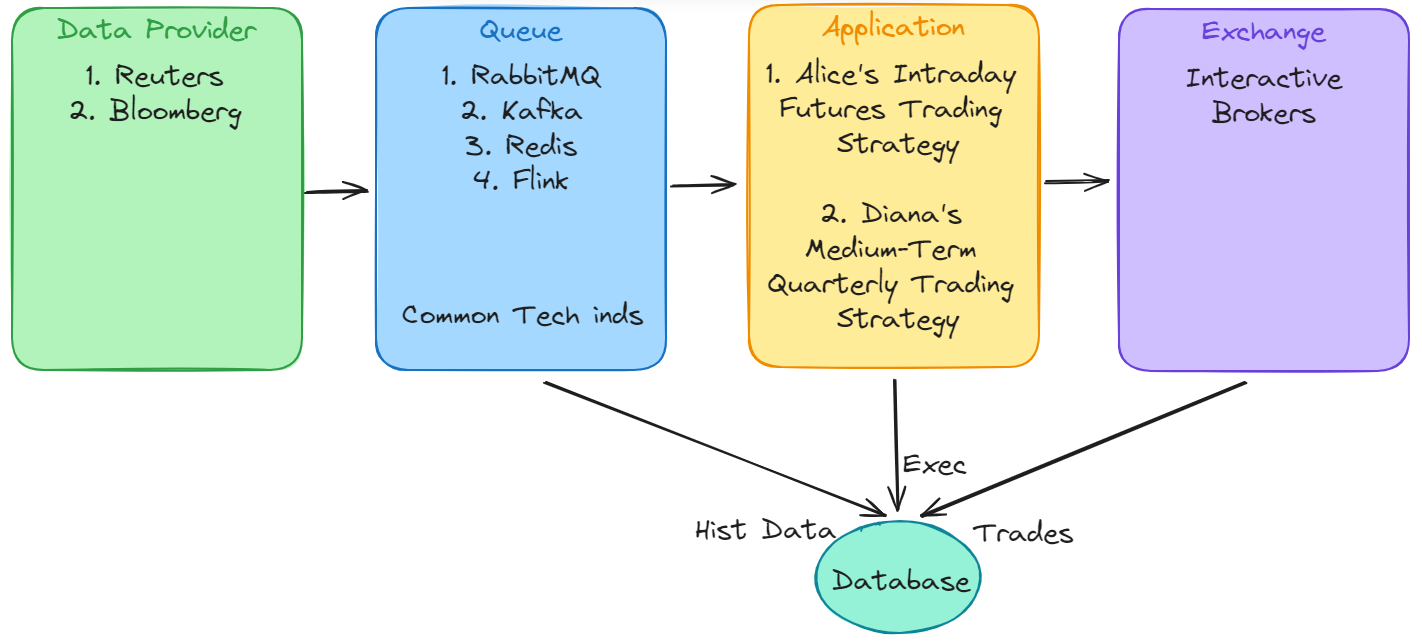
Whether using EC2 or SageMaker container deployment, both options serve to expedite development time. However, considering the overall efficiency of the trading system, two factors need to be considered: streaming data processing and the layer at which computations are performed.
The key to achieving higher efficiency lies in the Queue layer.
After the Data Provider delivers streaming data, the Queue distributes the data to the Application while simultaneously storing the streaming data in a database. This reduces latency and improves overall efficiency.
Furthermore, performing computations at the Queue layer for the technical indicators used by all Applications prevents redundant calculations and enhances overall efficiency.
However, further investigation is required to determine which Queue framework to use.
Summary
The theme of AWS re:Invent re:Cap, “Gen AI,” was a captivating event. There were many intriguing segments, such as the “Deep Dive Lounge,” “Lighting Talk,” and “Game Jam,” which provided delightful surprises.
Deep Dive Lounge, Wing So.
More importantly, numerous AWS solution architects have contributed to the advancement of my trading endeavors, offering lower-cost solutions and improved computational efficiency. Lastly, I would like to express my special thanks to Raymond Tsang, Yanwei CUI, and Wing So for their invaluable assistance.
In this article, I will first demonstrate the complete architecture of SageMaker.
Then, I will explain the reasons for using Multi-Modal-Single-Container + Microservices and not using Application Load Balancer.
Finally, I will use two different trading strategies to explain the best practices of data parallelism and model parallelism in advanced training models.
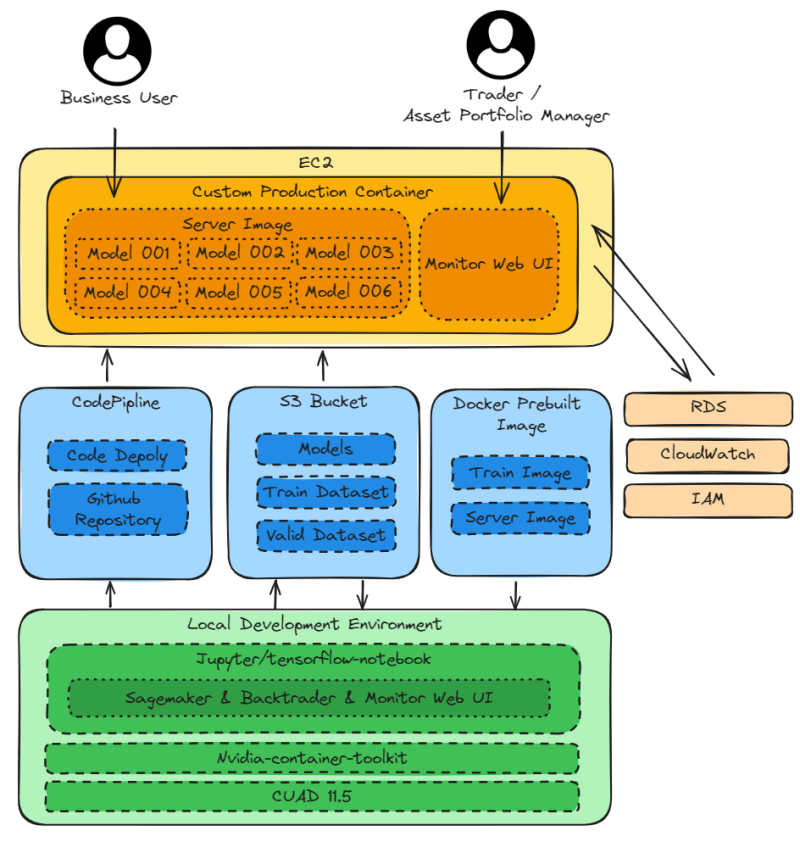
Architecture Overview
Local Development Environment
CUDA 11.5 and Nvidia-container-toolkit for local model training.
jupyter/tensorflow-notebook for local development environment, with libraries required for Sagemaker[local], Backtrader, and Monitor Web UI installed in the image.
Supported AWS services
Sagemaker prebuilt images for pulling images to the local development environment for local model training and testing.
S3 Bucket for storing datasets and models.
CodePipline for deploying projects on Github to EC2 production environment.
EC2
Custom Production Container with libraries required for Sagemaker, Backtrader, and Monitor Web UI.
Monitor Web UI for presenting the trading performance of the model in graphical form, providing :80 to Trader and Asset Portfolio Manager.
Server Image for deploying models using Sagemaker prebuilt image, providing :8080 to business user.
Managed AWS Services
RDS for storing model results. Monitor Web UI in EC2 retrieves the data from RDS and presents the trading performance in graphical form.
CloudWatch for monitoring the computation and storage of EC2, RDS, and S3 Bucket.
IAM for helping jupyter/tensorflow-notebook in local development environment to access Sagemaker prebuilt images and S3 Bucket.
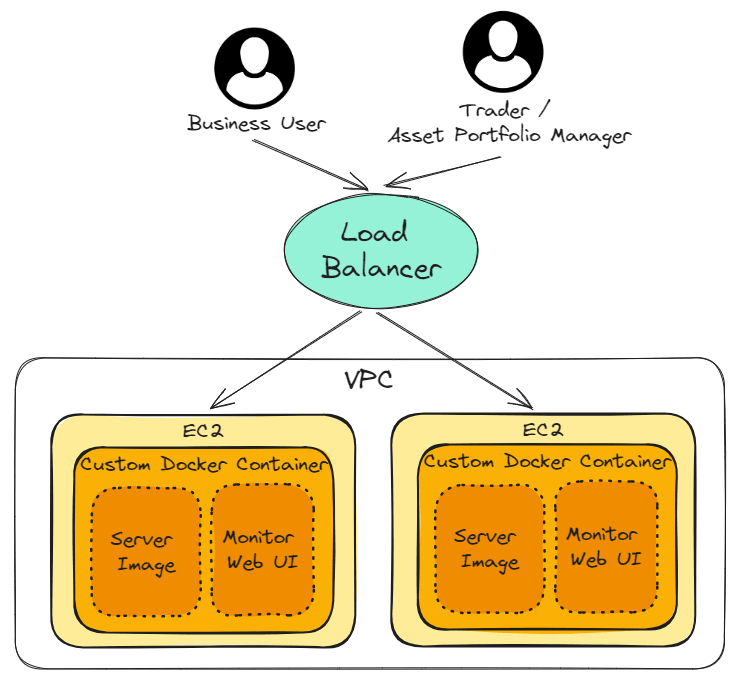
Why not use Application Load Balancer and instead create Multi-Modal-Single-Container + Microservices on EC2 to handle errors?
Application Load Balancer is a remarkable service. In fact, it can also be used to handle errors. However, in the case of trading strategies, I would choose to handle errors with Multi-Modal-Single-Container + Microservices.
Here are my three error handling methods:
The goal of the following three error handling methods is to flexibly reduce hardware resource requirements.
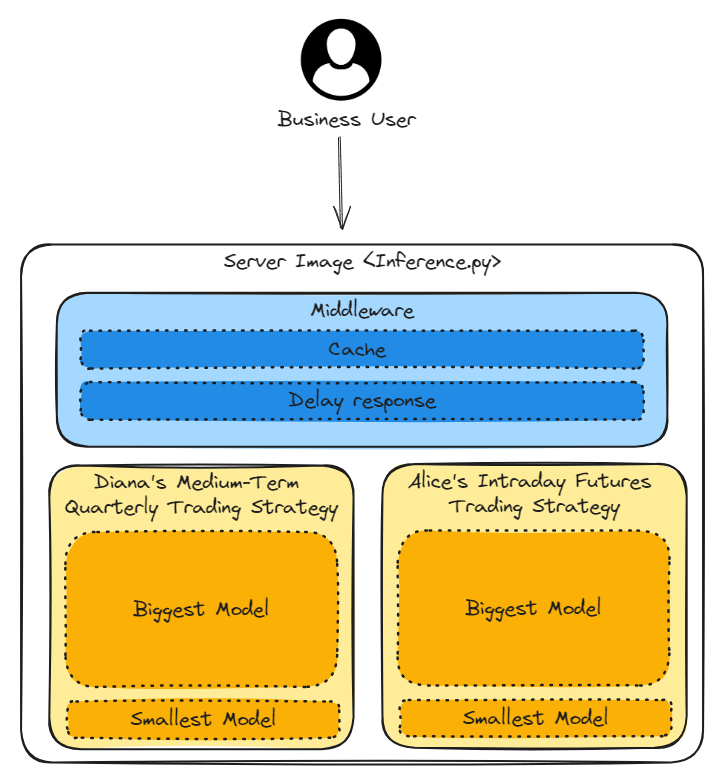
1.Switch to Smallest Model
There are two trading strategies (Diana’s medium-term quarterly trading strategy and Alice’s intraday futures trading strategy). Each trading strategy has two versions of the model, where the Biggest Model provides high accuracy but requires high hardware resources. On the contrary, the Smallest Model provides low accuracy but requires low hardware resources.
If the server is in a high computational state, switching to the Smallest Model can reduce the hardware resource requirements and keep the application running smoothly.
2. Response caching results
When the same business user uses the application frequently, returning cached data can avoid overloading hardware resources.
3. Delayed Response time
When hardware resources are overloaded, delaying the response time can release the hardware resources.
Advantages of Multi-Modal-Single-Container + Microservices
Here are my examples of trading strategies to explain the reasons for using Multi-Modal-Single-Container + Microservices.
1.Trading strategies have high fault tolerance
Both trading strategies anticipate reduced profits due to slippage during trading. This design with high fault tolerance can accommodate various hardware issues, such as switching to the Smallest Model, response caching results, and delayed response time.
Additionally, it can handle errors from market makers, such as delayed quotes, partial executions, and wide bid-ask spreads.
2. Shared hardware resources
The frequency and time of use of two trading strategies are different, allowing for full utilization of idle hardware resources.
3. Deployment of trading strategies in different regions
Diana’s medium-term quarterly trading strategy targets global assets. By deploying trading strategies independently in Hong Kong and the United States, the latency can be reduced.
Furthermore, if the hardware in Hong Kong completely stops working, the hardware in the United States can be used to hedge the risk by purchasing short options of overseas ETF.
Best Practices of Data Parallelism and Model Parallelism in Advanced Training Models
Sagemaker provides remarkable advanced training methods: Data parallelism and Model parallelism. I will use two different trading strategies to explain the best practices of data parallelism and model parallelism in advanced training models.
Data parallelism
Model parallelism
Model Parallelism: A simple method of model parallelism is to explicitly assign layers of the model onto different devices.
Data Parallelism: Each individual training process has a copy of the global model but trains it on a unique slice of data in parallel with others.
– Accelerate Deep Learning Workloads with Amazon SageMaker, chapter10
In simple terms, if the data can be divided into small groups, Data parallelism is used. If the model can be divided into small groups, Model parallelism is used.
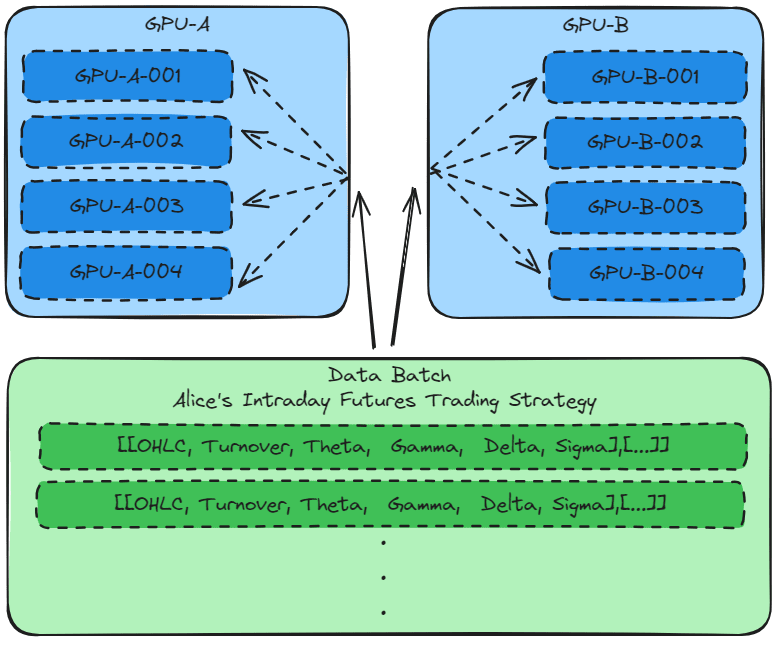
Alice’s intraday futures trading strategy
The intraday trading strategy mainly uses a few key indicators to train the model, providing entry and exit points. Therefore, the data samples are large.
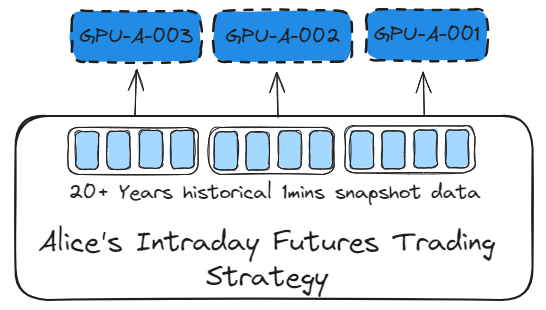
When the data sample is large and the model has only a few algorithms, Data parallelism should be used to train the model. This allows the data set to be split and computed on different GPUs.
Sagemaker provides remarkable advanced training methods. By setting the distribution parameter, Data parallelism can be used to train the model.
Diana’s Medium-Term Quarterly Trading Strategy
The macro trading strategy mainly uses dozens of key indicators to provide overseas asset allocation forecasts. The minimum data set is 8 years (2 bull and bear cycles) of hourly snapshot data.
When the main algorithms can be split into small groups, Model parallelism is used to train the model. This allows the model tensor to be computed in batches on different GPUs.
Similarly, by setting the distribution parameter, Model parallelism can be used to train the model.
Conclusion
AWS provides convenient solutions for the financial industry. Sagemaker seamlessly integrates deep learning workflow into production environments. Additionally, Sagemaker offers surprising features to accelerate development. I will continue to learn about new AWS products and share examples of AWS services in finance and trading.
In this article, I will first present a simple example to demonstrate the process of training and deploying models locally using Sagemaker.
Then, I will share my experience with a LSTM futures trading project to explain the best practices for using real-time endpoints and batch-transform endpoints.
Finally, based on my experience with the LSTM futures trading project, I will explain which Sagemaker Instance / Fargate / EC2 should be selected for deployment.
Sagemaker Exec - Training and Deploying Models Locally
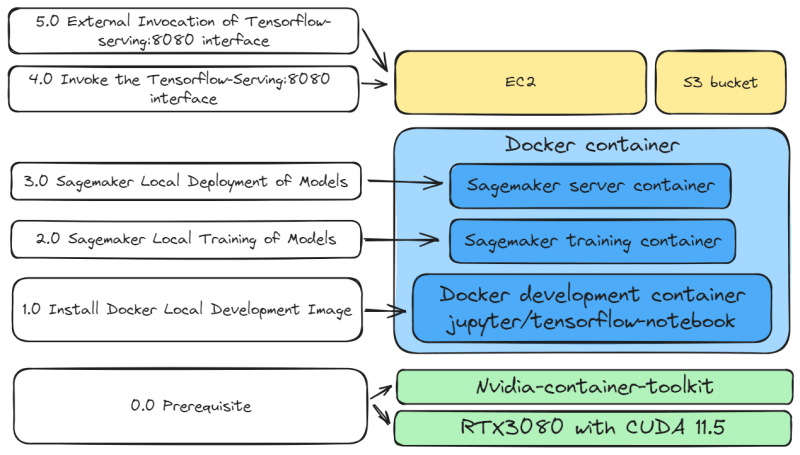
0.0 Prerequisite: Before starting local development, please install the following:
# Copyright (c) Jupyter Development Team. # Distributed under the terms of the Modified BSD License. ARG REGISTRY=quay.io ARG OWNER=jupyter ARG BASE_CONTAINER=$REGISTRY/$OWNER/scipy-notebook FROM $BASE_CONTAINER
1.4 Start the local development image 1.5 -v /home/jovyan/work, this is the default path for jupyter/tensorflow-notebook 1.6 -v /var/run/docker.sock, used to start the Sagemaker’s train & inference image 1.7 -v /tmp, this is the temporary file path for Sagemaker 1.8 Go to 127.0.0.1:8888
This is a simple example demonstrating the process of training and deploying models locally using Sagemaker. As mentioned earlier, since Sagemaker does not fully support local development, it is necessary to modify the jupyter/tensorflow-notebook image. Additionally, a more complex inference.py is required for local model deployment.
However, I still recommend using Sagemaker for local development because it provides pre-built resources and clean code. Moreover, Sagemaker has preconfigured workflows for training and deploying model images, so we do not need to deeply understand the project structure and internal operations to complete the training and deployment of models.
When to use real-time endpoints and batch-transform endpoints
The choice of endpoint depends not only on cost factors but also on business logic, such as response time, frequency of Invocation, dataset size, model update frequency, error tolerance, etc. I will present two practical use cases to explain the best use of real-time endpoints and batch-transform endpoints.
SageMaker batch transform is designed to perform batch inference at scale and is cost-effective.
SageMaker real-time endpoints aim to provide a robust live hosting option for your ML use cases.
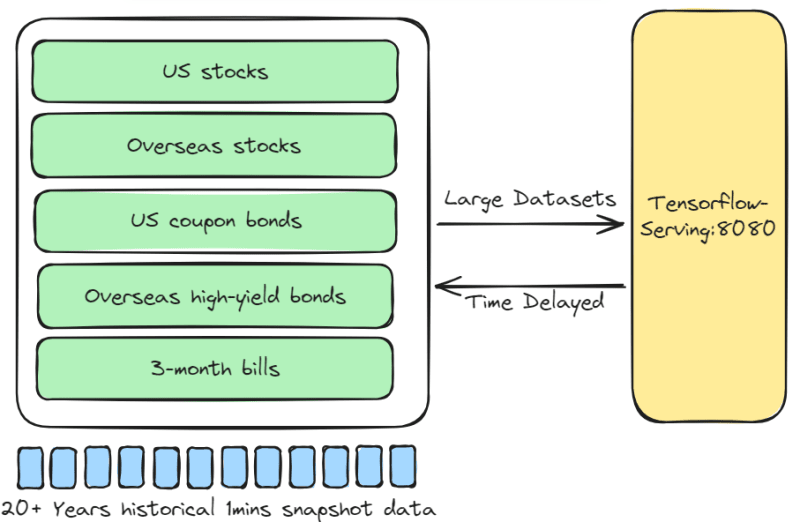
1. Diana’s medium-term quarterly trading strategy The multi-asset portfolio includes US stocks, overseas stocks, US coupon bonds, overseas high-yield bonds, and 3-month bills. Every 3 months, the LSTM-all-weather-portfolio model is used for asset rebalancing. This model runs once a day, 15 minutes before market close, to check the risk of each position and whether the portfolio meets the 5% annualized return.
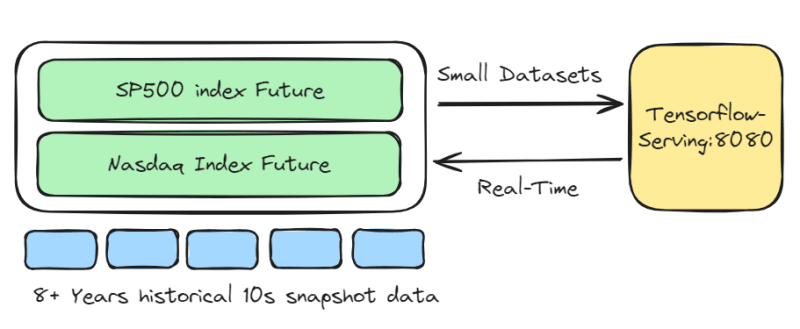
2. Alice’s intraday futures trading strategy Trading only S&P 500 index and Nasdaq index futures, with a holding period of approximately 30 minutes to 360 minutes. The LSTM-Pure-Alpha-Future model uses 20-second snapshot data to provide buy and exit signals. These signals are stored for daily performance analysis of the model.
Diana’s Medium-Term Quarterly Trading Strategy
Assets: Stocks, Bonds, Bills
Instrument Pool: US stocks, Overseas stocks, US coupon bonds, Overseas high-yield bonds, 3-month bills
Trading Frequency: 5 trades per quarter
Response Time: Time Delayed. Only required 15 minutes before market close
Model: LSTM-all-weather-portfolio
Model Update Frequency: Low. Update the model only if it achieves a 5% annualized return
Recommended Solution: Batch-transform endpoint
If the dataset is large and response time can be delayed, the Batch-transform endpoint should be used.
Alice’s Intraday Futures Trading Strategy
Assets: Index Futures
Instrument Pool: SP500 index Future, Nasdaq Index Future
Trading Frequency: 5 trades per day
Response Time: Real-time
Model: LSTM-Pure-Alpha-Future
Model Update Frequency: High. Always optimization of buy and exit signals
Recommended Solution: Real-time endpoint
If the dataset is small and response time needs to be fast, the Real-time endpoint should be used.
Even though Sagemaker provides various deployment benefits, why do I still use EC2?
In my current role at a financial technology company, I am always excited about innovative products. AWS’s innovative products bring surprising solutions. If I were to create a personal music brand, I would choose AWS’s new products such as DeepComposer, Fargate, Amplify, Lambda, etc.
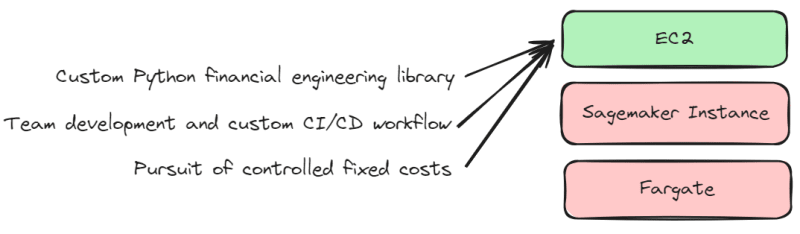
However, the cost of migrating to the cloud is high. Additionally, there is no significant incentive to migrate existing hardware resources to the cloud. Here are my use cases to explain why I choose EC2:
1. Custom Python financial engineering library
Although I prefer to use frameworks and libraries, there are some special requirements that require the use of a custom Python financial engineering library, such as developing high dividend investment strategies, macro cross-market analysis, and so on. Therefore, I manage Docker images. Thus, the pre-built images provided by Sagemaker cannot fully meet my needs, and instead, EC2 offers more freedom to structure the production environment.
2. Team development and custom CI/CD workflow
Although Sagemaker allows for quick training and deployment of models, it does not fully meet my development needs. We have an independent development team responsible for researching trading strategies and developing deep learning trading models. Due to our custom CI/CD workflow, it is not suitable to overly rely on Sagemaker for architecture.
3. Pursuit of controlled fixed costs
Although Sagemaker and Fargate allow for quick creation of instances, the cost is based on CPU utilization. Therefore, I prefer EC2 with fixed costs and manually scale up when resources are insufficient.
Conclusion
Sagemaker is a remarkable product. For startup companies looking to launch new products, AWS’s cloud solution is the preferred choice. Even for mature enterprises, leveraging AWS cloud services can optimize workflow. In summary, I highly recommend incorporating Sagemaker into the development process.
If I have a local server with an RTX3080 and 64GB of memory, do I still need AWS Sagemaker? The answer is: yes, there is still a need.
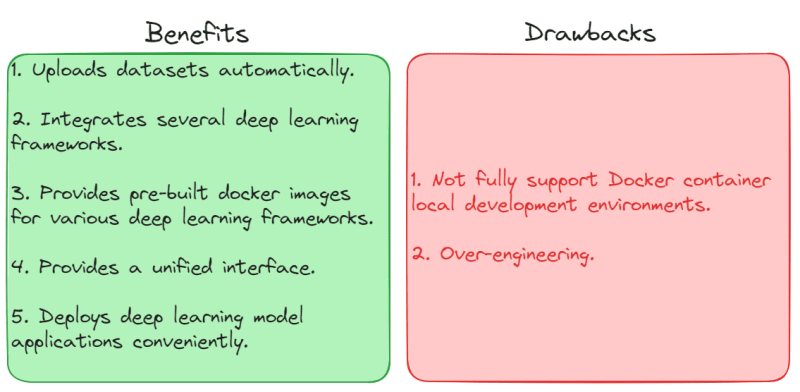
Although the hardware level of the local server is good, Sagemaker provides additional benefits that are particularly suitable for team development processes. These benefits include:
Sagemaker automatically uploads datasets (training set, validation set) to S3 buckets, with a timestamp suffix each time a model is trained. This makes it easy to manage data sources during a long-term development process.
Sagemaker integrates several popular deep learning frameworks, such as TensorFlow and XGBoost. This ensures code consistency.
Sagemaker provides pre-built docker images for various deep learning frameworks, including training images and server images, which accelerate local development time.
The inference.py in Sagemaker’s server image ensures a unified interface specification for models. Code consistency and simplicity are crucial in team development.
Sagemaker itself is a cloud service, making it convenient to deploy deep learning model applications.
However, Sagemaker has some drawbacks when it comes to training and deploying models locally. These drawbacks include:
Sagemaker does not fully support Docker container local development environments. In other words, using the jupyter/tensorflow-notebook image to develop Sagemaker sometimes generates minor issues. I will discuss this in more detail below.
Over-engineering. Honestly, although I am a supporter of Occam’s Razor and prefer solving practical problems with the simplest code, setting up Sagemaker on a local server can be somewhat over-engineered in terms of infrastructure.
In summary, for long-term team development, it is necessary to spend time setting up Sagemaker locally in the short term.
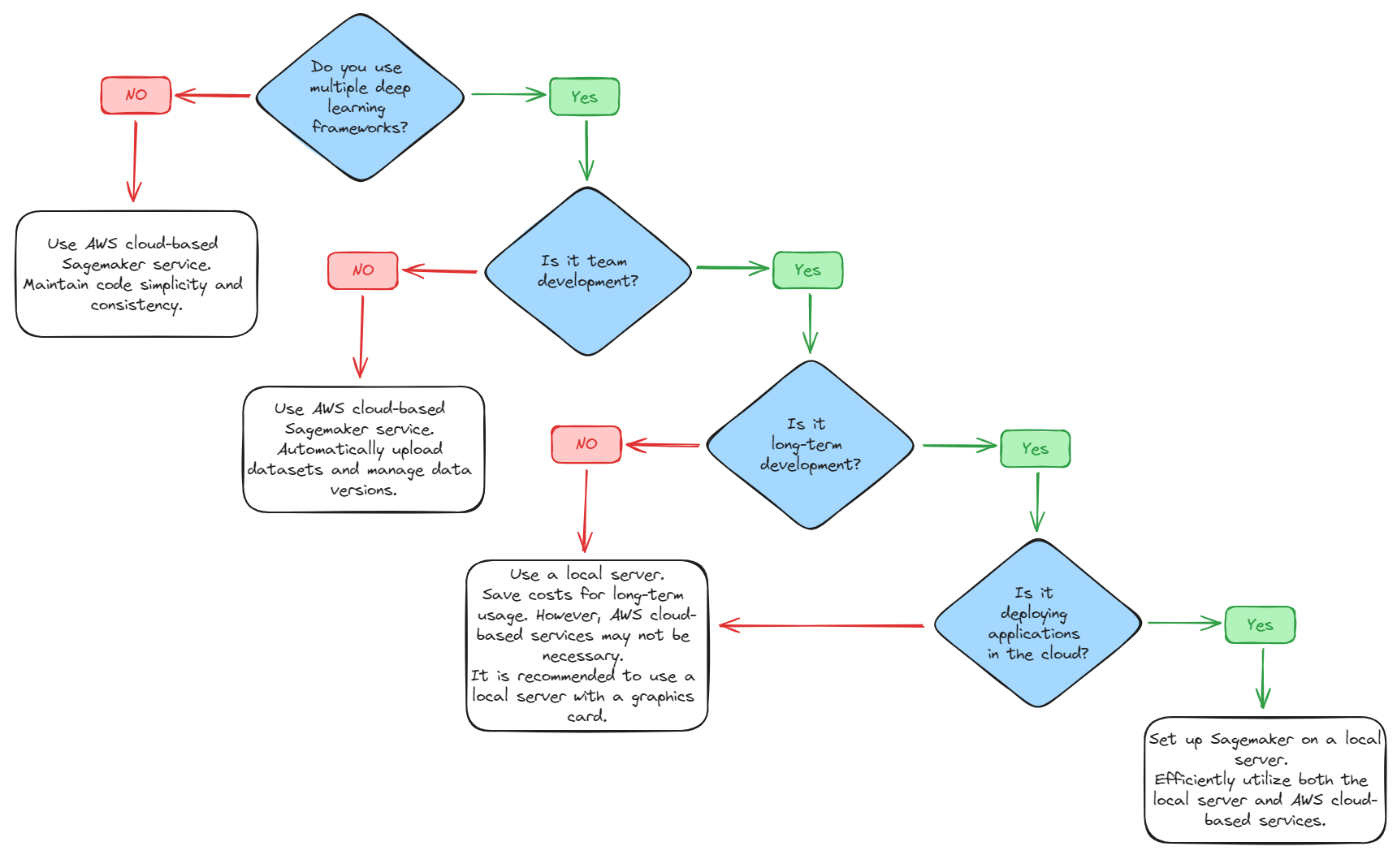
How to decide whether to set up Sagemaker on a local server?
1. Do you use multiple deep learning frameworks? No -> Use AWS cloud-based Sagemaker service. Maintain code simplicity and consistency. Yes -> Go to question 2.
2. Is it team development? No -> Use AWS cloud-based Sagemaker service. Automatically upload datasets and manage data versions. Yes -> Go to question 3.
3. Is it long-term development? No -> Use a local server. Save costs for long-term usage. However, AWS cloud-based services may not be necessary. It is recommended to use a local server with a graphics card. Yes -> Go to question 4.
4. Is it deploying applications in the cloud? No -> Use a local server. Yes -> Set up Sagemaker on a local server. Efficiently utilize both the local server and AWS cloud-based services.
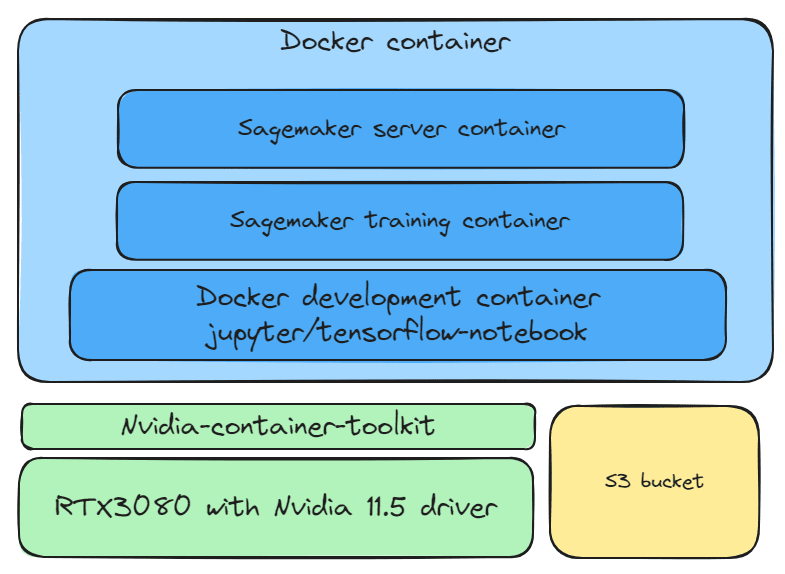
Local Server Architecture
Nvidia 11.5 driver. RTX3080 is required for both training and deploying models.
Nvidia-container-toolkit, connecting Docker images with Nvidia 11.5 driver.
Docker development container environment, jupyter/tensorflow-notebook. Use Sagemaker to develop TensorFlow deep learning models.
Sagemaker training image. Sagemaker uses pre-built images to train models, automatically selecting suitable images for Nvidia, Python, and TensorFlow. Since I use TensorFlow, I use 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:2.11-gpu-py39.
Sagemaker server image. Sagemaker uses pre-built images to deploy models. This server image utilizes TensorFlow-serving (https://github.com/tensorflow/serving) and Sagemaker’s inference for model deployment. Since I use TensorFlow, I use 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:2.11-gpu.
S3 bucket. Used to centrally manage datasets and model versions.
Useful Tips
Although these tips are very basic, in fast iteration cycles and team development, simple and practical tips can make development smoother and more efficient.
Clear naming As the project develops over time, the number of dataset and model versions increases. Therefore, clear file naming conventions help maintain development efficiency.
1. Prefix
{Project Name}-{Model Type}-{Solution}
Whether it’s a dataset, model, or any temporary .csv file, it is best to have clear names to avoid forgetting the source and purpose of those files. Here are some examples of naming conventions I use.
After each model training, there are often new ideas. For example, when optimizing a LSTM model used for stock trading strategies by adding new momentum indicators, I would add this optimization approach to the suffix.
{volSignal}-{20240106_130400}
If there are no specific updates, generally, I use numbers to represent the current version.
{a.1}-{20240106_130400}
3. Clear project structure
./data/input
Datasets inputted into the model.
./data/output
Model outputs.
./data/tmp
All temporary files. In fast iteration cycles, it is common to lose temporary files, leading to a loss of data source traceability. Therefore, temporary files also need to be well managed.
./model
Location for storing models. Generally, Sagemaker automatically manages datasets and models, but it is still recommended to store them locally for convenient team development.
./src
Supporting libraries, such as Sagemaker’s inference.py, and common toolkits for model training.
Practical Experience: Why Sagemaker Does Not Fully Support Local Docker Container Development
The support of Sagemaker for local development is not very favorable. Below are two local development issues that I have encountered. Although I have found similar issues raised on Github, there is still no satisfactory solution available at present.
1. Issue with local container Tensorflow-Jupyter development environment
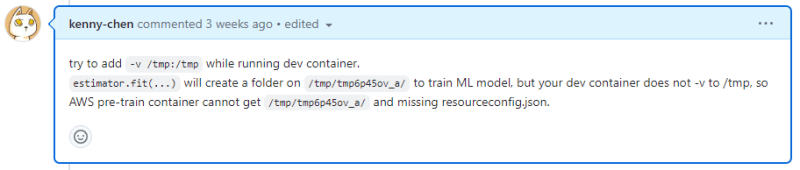
When training models, Sagemaker displays an error regarding the docker container (No /opt/ml/input/config/resourceconfig.json).
The main reason is that after executing estimator.fit(...), Sagemaker’s Training image reads temporary files in the /tmp path. However, Sagemaker does not consider the local container Tensorflow-Jupyter. As a result, these temporary files in /tmp are only available in the local container Tensorflow-Jupyter, causing errors when the Training image of Sagemaker tries to read them.
Solution: When launching the local container Tensorflow-Jupyter, add the "-v /tmp:/tmp" command to link the local container’s /tmp with the local /tmp, which solves this problem.
Here is the code I used to launch the local container: sudo docker run --privileged --name jupyter.sagemaker.001 --gpus all -e GRANT_SUDO=yes --user root --network host -it -v /home/jovyan/work:/home/jovyan/work -v /sagemaker:/sagemaker -v /var/run/docker.sock:/var/run/docker.sock -v /tmp:/tmp -v /sagemaker:/sagemaker sagemaker/local:0.2 >> /home/jovyan/work/log/sagemaker_local_date +\%Y\%m\%d_\%H\%M\%S.log 2
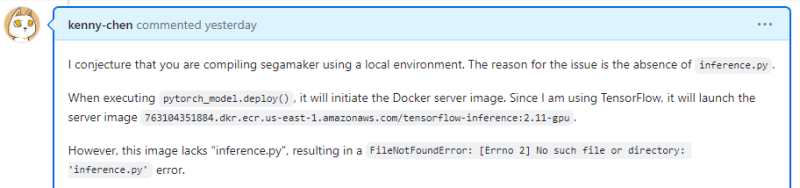
2. Issue with Sagemaker’s local server image Sagemaker’s local server image defaults to using the inference method for deployment, so there is no inference.py in the server image. Therefore, model.fit(...) followed by model.deploy(...) results in errors.
The error messages are not clear either. Sometimes, it displays "/ping" error, and other times, "No such file or directory: 'inference.py'" error.
Solution: Save the model after model.deploy(...). Then, use sagemaker.tensorflow.TensorFlowModel(...) to reload the model and reference ./src/inference.py.
Although the inference method is a more convoluted way to locally deploy models, it is useful for adding middleware business logic on the server side and is a very valuable local deployment approach.
Summary
I know that Sagemaker’s cloud service offers many amazing services, such as preprocessing data, batch training, Sagemaker-TensorBoard, and more. For developers who need to quickly prototype, these magical services are perfect for them.
Although setting up Sagemaker architecture on a local server may be more complex, Sagemaker provides standardized structure, automated processes, integrated unified interfaces, and pre-built resources. In the long run, I recommend setting up Sagemaker on a local server.
 Deep Dive Lounge, Wing So.
Deep Dive Lounge, Wing So.